Ever felt the ground drop beneath you when your computer crashes, the power goes out, or a flight gets canceled? That’s the chilling reality of a system failure—silent, sudden, and often devastating. In our hyper-connected world, systems keep everything running, and when they break, chaos follows.


What Exactly Is a System Failure?

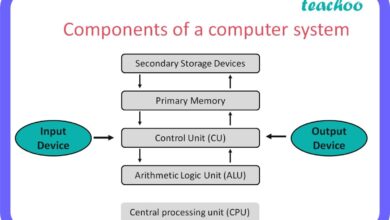
A system failure occurs when a complex network of components—be it technological, organizational, or biological—ceases to function as intended. It’s not just a glitch; it’s a breakdown in the entire structure that supports a process or service. These failures can ripple across industries, economies, and even societies.
Defining System Failure in Technical Terms
In engineering and computer science, a system failure is formally defined as the inability of a system to perform its required functions within specified limits. This could mean a server crashing under load, a power grid collapsing, or a manufacturing line halting unexpectedly. The key is that the system as a whole fails, not just a single part.
- Failure can be total or partial.
- It may be temporary or permanent.
- It often involves multiple interdependent components.
According to the ISO/IEC 23030 standard, system resilience is measured by how quickly a system can recover from such failures.
Types of System Failures
Not all system failures are created equal. They vary by cause, scope, and impact. Common types include:
Hardware Failure: Physical components like servers, routers, or turbines malfunction.Software Failure: Bugs, crashes, or design flaws in code lead to unexpected behavior.Network Failure: Communication links break down, disrupting data flow.Human-Induced Failure: Errors in operation, configuration, or decision-making trigger collapse.Environmental Failure: Natural disasters or extreme conditions overwhelm system tolerances.”A system failure is not the failure of a part, but the failure of the whole to hold together.” — Dr.
.Nancy Leveson, MIT Professor of Aeronautics and Astronautics
Real-World Examples of System Failure
History is littered with infamous system failures.The 2003 Northeast Blackout affected 55 million people due to a software bug and poor monitoring.The 2010 Flash Crash wiped $1 trillion off U.S.stock markets in minutes due to algorithmic trading errors.These weren’t isolated incidents—they were systemic breakdowns..
Another example is the 2023 FAA system failure that grounded all U.S. flights due to a corrupted database update. This wasn’t just a technical hiccup; it was a national disruption.
Common Causes of System Failure
Understanding why system failures happen is the first step toward preventing them. While causes vary, several recurring themes emerge across industries and technologies.
Poor Design and Architecture
Many system failures stem from flawed initial design. Systems built without redundancy, scalability, or fail-safes are ticking time bombs. For example, a database without backup protocols will collapse under data loss.
- Lack of modular design increases vulnerability.
- Over-reliance on single points of failure (SPOFs) is a common architectural flaw.
- Inadequate stress testing during development leads to real-world collapse.
The Apollo 13 mission nearly ended in disaster due to an oxygen tank design flaw—proof that even elite systems can fail due to poor engineering choices.
Software Bugs and Glitches
Software is inherently complex, and even minor bugs can trigger massive system failure. The 1999 Mars Climate Orbiter was lost due to a unit conversion error—pounds vs. newtons—costing $125 million.
- Unpatched vulnerabilities allow exploits.
- Race conditions and memory leaks cause crashes.
- Poor code documentation makes debugging harder.
Modern systems rely on millions of lines of code; a single misplaced semicolon can cascade into catastrophe.
Human Error and Operational Mistakes
Humans are often the weakest link. Misconfigurations, accidental deletions, or incorrect commands can bring down entire networks. In 2017, an Amazon S3 outage was caused by a typo during a debugging session, affecting thousands of websites.
- Lack of training increases error rates.
- Overworked staff make more mistakes.
- Poor communication during crises worsens outcomes.
“The root cause was a simple typo, but the impact was global.” — Amazon Web Services Post-Mortem Report
System Failure in Technology and IT Infrastructure
In the digital age, IT systems are the backbone of business, government, and daily life. When they fail, the consequences are immediate and far-reaching.
Data Center Outages
Data centers house the servers that power the internet. A failure here can knock out email, cloud storage, and e-commerce platforms. In 2021, a fire at a French data center operated by OVHcloud destroyed four buildings and took 3.6 million websites offline.
- Power supply failures are a leading cause.
- Cooling system malfunctions lead to overheating.
- Fire suppression systems can sometimes cause more damage than the fire itself.
Redundant power sources, geographic distribution, and real-time monitoring are critical defenses.
Cloud Service Disruptions
As more companies migrate to the cloud, reliance on providers like AWS, Google Cloud, and Microsoft Azure grows. But when these platforms fail, the ripple effect is enormous.
- AWS outages in 2017 and 2021 disrupted Netflix, Slack, and Airbnb.
- Cloud misconfigurations expose data to breaches.
- Dependency on a single provider increases risk.
Organizations must adopt multi-cloud strategies and robust disaster recovery plans to mitigate cloud-based system failure.
Cybersecurity Breaches as System Failure
Cyberattacks don’t just steal data—they can cripple entire systems. Ransomware attacks, like the 2021 Colonial Pipeline incident, force shutdowns and create national emergencies.
- Zero-day exploits bypass traditional defenses.
- Phishing attacks trick employees into granting access.
- DDoS attacks overwhelm servers with traffic.
The line between cyberattack and system failure is blurring. A successful breach often leads to cascading failures across networks.
System Failure in Critical Infrastructure
When systems supporting essential services fail, lives are at risk. Power grids, transportation networks, and healthcare systems must be resilient by design.
Power Grid Collapse
Electricity is the lifeblood of modern society. Grid failures can stem from equipment failure, cyberattacks, or natural disasters. The 2003 Northeast Blackout was triggered by a software bug and tree branches touching power lines—a perfect storm of small failures leading to massive collapse.
- Aging infrastructure increases vulnerability.
- Lack of real-time monitoring delays response.
- Interconnected grids mean failures spread quickly.
Smart grids with AI-driven monitoring and self-healing capabilities are being developed to prevent future system failure.
Transportation System Breakdowns
From air traffic control to subway signaling, transportation relies on precise, synchronized systems. A single failure can halt movement across cities.
- The 2023 FAA NOTAM system failure grounded all U.S. flights.
- London Underground signaling failures cause daily delays.
- Autonomous vehicle software bugs raise safety concerns.
Redundancy, real-time diagnostics, and human oversight are essential to maintaining reliability.
Healthcare System Failures
Hospitals depend on IT systems for patient records, diagnostics, and life support. When these fail, patient safety is compromised.
- Ransomware attacks on hospitals have delayed surgeries.
- EMR (Electronic Medical Record) system crashes disrupt care.
- Medical device connectivity issues can be fatal.
The UK’s NHS has faced repeated system failures due to outdated IT infrastructure, highlighting the need for investment in resilient healthcare systems.
Organizational and Management System Failures
Not all system failures are technical. Poor leadership, flawed processes, and cultural issues can cause organizations to collapse from within.
Bureaucratic Inefficiency
Excessive red tape, slow decision-making, and lack of accountability can paralyze institutions. The U.S. government’s slow response to Hurricane Katrina in 2005 was a textbook case of organizational system failure.
- Overlapping jurisdictions create confusion.
- Poor communication channels delay action.
- Rigid hierarchies prevent rapid adaptation.
Agile management models and decentralized decision-making can improve responsiveness.
Corporate Governance Failures
Enron, Lehman Brothers, and Theranos all collapsed due to governance failures—fraud, lack of oversight, and unethical leadership. These weren’t just financial meltdowns; they were systemic breakdowns in trust and accountability.
- Board complacency allows risky behavior.
- Short-term profit focus undermines long-term stability.
- Whistleblower suppression hides problems.
Strong internal controls, independent audits, and ethical leadership are vital safeguards.
Cultural and Communication Breakdowns
When teams don’t communicate, systems fail. NASA’s Challenger disaster in 1986 was partly due to engineers’ warnings being ignored by management. A culture that discourages dissent leads to catastrophic oversight.
- Silos between departments prevent information sharing.
- Fear of retaliation silences concerns.
- Lack of psychological safety reduces innovation.
“It’s not the failure to predict, but the failure to listen, that kills systems.” — Diane Vaughan, Sociologist and Author of ‘The Challenger Launch Decision’
Biological and Ecological System Failures
Systems aren’t just man-made. Natural ecosystems and biological organisms also experience failure when balance is disrupted.
Organ Failure in the Human Body
The human body is a complex system. Organ failure—like heart, liver, or kidney failure—occurs when a critical component can no longer perform its function. This can be due to disease, trauma, or systemic stress.
- Chronic conditions like diabetes lead to multi-organ failure.
- Septic shock causes cascading organ shutdown.
- Medical interventions can sometimes trigger failure (e.g., drug toxicity).
Preventive care, early diagnosis, and integrated healthcare approaches are key to avoiding biological system failure.
Ecological Collapse
Ecosystems rely on delicate balances. Overfishing, deforestation, and climate change can push them past tipping points. The collapse of the Atlantic cod fishery in the 1990s is a stark example of ecological system failure.
- Biodiversity loss reduces resilience.
- Pollution disrupts food chains.
- Climate change accelerates habitat destruction.
Restoration efforts, sustainable practices, and global cooperation are needed to prevent irreversible damage.
Pandemics as Systemic Health Crises
The COVID-19 pandemic exposed weaknesses in global health systems. Supply chain breakdowns, overwhelmed hospitals, and misinformation created a perfect storm of system failure.
- Lack of preparedness led to PPE shortages.
- Vaccine distribution was uneven and slow.
- Public trust in institutions eroded.
The World Health Organization now emphasizes the need for a global health architecture capable of withstanding future shocks.
Preventing and Mitigating System Failure
While no system is immune to failure, smart strategies can reduce risk and speed recovery.
Redundancy and Fail-Safe Mechanisms
Redundancy means having backup components that take over when primary ones fail. Aircraft have multiple flight control systems; data centers have backup generators.
- N+1 redundancy ensures at least one spare component.
- Geographic redundancy protects against local disasters.
- Failover systems automatically switch to backups.
The principle is simple: never rely on a single point of anything.
Regular Maintenance and Monitoring
Preventive maintenance catches issues before they escalate. Continuous monitoring with AI and machine learning can predict failures before they happen.
- Predictive analytics analyze system behavior for anomalies.
- Automated alerts notify teams of potential issues.
- Scheduled updates and patches prevent known vulnerabilities.
Proactive care is far cheaper than reactive repair.
Incident Response and Disaster Recovery Planning
When failure occurs, having a plan is crucial. Incident response teams, recovery protocols, and communication strategies minimize damage.
- Disaster recovery sites allow quick restoration of services.
- Regular drills ensure teams are prepared.
- Post-mortem analysis prevents repeat failures.
Every organization should have a documented, tested, and updated disaster recovery plan.
The Future of System Resilience
As systems grow more complex, so must our approaches to protecting them. The future lies in adaptive, self-healing, and intelligent systems.
AI and Machine Learning in Failure Prediction
AI can analyze vast datasets to detect patterns indicative of impending failure. Google uses AI to predict hardware failures in its data centers before they happen.
- Anomaly detection identifies unusual behavior.
- Predictive maintenance schedules are optimized by AI.
- Natural language processing monitors logs for early warnings.
The integration of AI into system management is transforming how we prevent system failure.
Blockchain for System Integrity
Blockchain’s decentralized and immutable ledger can enhance system reliability. In supply chains, it ensures traceability; in voting systems, it prevents tampering.
- Transparency reduces fraud.
- Distributed consensus prevents single-point manipulation.
- Smart contracts automate responses to system events.
While not a panacea, blockchain adds a layer of trust and resilience.
Designing for Antifragility
Nassim Taleb introduced the concept of antifragility—systems that improve under stress. Unlike resilience (which resists failure), antifragile systems grow stronger from shocks.
- Stress-testing systems reveals hidden weaknesses.
- Controlled failures (like chaos engineering) build robustness.
- Feedback loops enable continuous improvement.
Companies like Netflix use chaos engineering tools like Chaos Monkey to deliberately break systems in testing, ensuring they can survive real failures.
What is a system failure?
A system failure occurs when a complex network of components stops functioning as intended, leading to disruption or collapse. It can be technical, organizational, or natural in origin.
What are common causes of system failure?
Common causes include poor design, software bugs, human error, cyberattacks, aging infrastructure, and environmental disasters. Often, multiple factors combine to trigger a failure.
How can system failures be prevented?
Prevention strategies include redundancy, regular maintenance, real-time monitoring, disaster recovery planning, and fostering a culture of accountability and transparency.
Can AI prevent system failure?
Yes, AI can predict failures by analyzing data patterns, automating responses, and optimizing maintenance schedules. However, it requires quality data and proper implementation.
What’s the difference between system failure and component failure?
Component failure affects a single part (e.g., a broken server), while system failure means the entire network or process stops working, often due to interdependencies and cascading effects.
System failure is an inevitable risk in any complex environment. Whether in technology, infrastructure, or human organizations, the key is not to eliminate failure—because that’s impossible—but to anticipate, mitigate, and recover from it. By understanding the causes, learning from past mistakes, and investing in resilient design, we can build systems that don’t just survive failure, but emerge stronger from it. The future belongs to those who prepare not for perfection, but for resilience.
Further Reading: